Pipeline
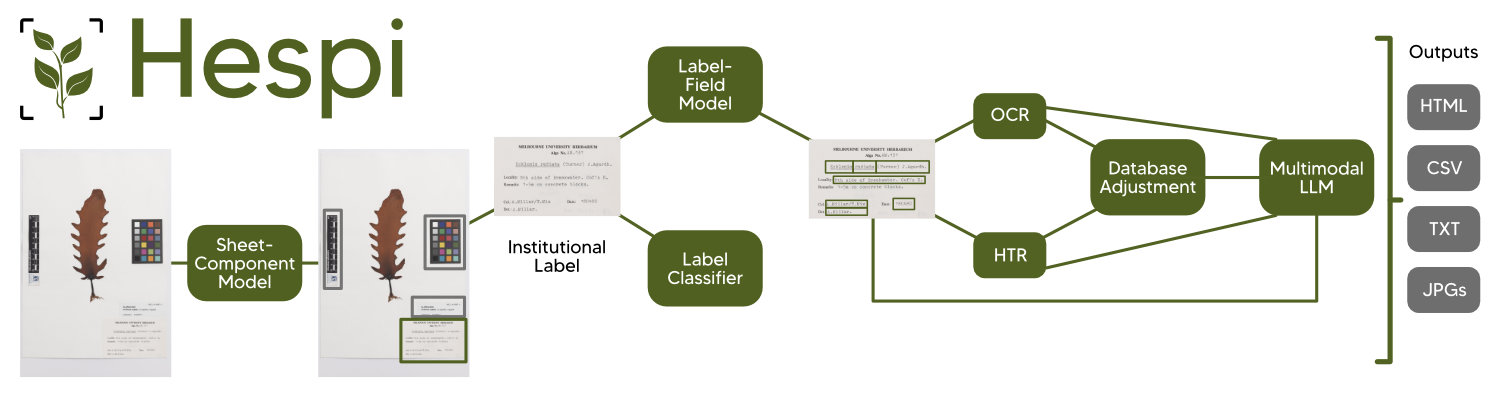
The Sheet-Component Model
This model takes specimen sheet images and outputs bounding boxes for 11 components:
primary specimen label
data on the specimen sheet outside of a label (‘original data’; often handwritten)
taxon and other annotation labels
stamps
swing tags attached to specimens
accession number (when outside the primary specimen label)
small database labels
medium database labels
full database labels
swatch
scale

The Label-Field Model
The Label-Field Model takes any primary specimen label detected from the Sheet-Component Model and detects bounding boxes for the following fields:
family
genus
species
infrasp_taxon
authority
collector_number
collector
locality
geolocation
year
month
day

Label Classifier
We have trained a classifier to detect the following types of writing on the primary specimen label:
typewriter
printed
handwritten
combination
Text Recognition
Each field detected by the Label-Field Model is input into the Text Recognition module. This uses the Tesseract Optical Character Recognition (OCR) engine and the TrOCR large HTR model.
Text formatting is applied to OCR results for the family, genus, and species fields, where the standardized taxa format is expected. Family and genus fields are changed to title case, species to lower case. For all three, punctuation marks are stripped from the beginning and end of the text, as well as any whitespace/empty characters.
For the family, genus, species and authority fields, any recognized text is cross-checked against the World Flora Online database, an international compendium of vascular plants and mosses, and against databases within the Australian National Species List, a nationally recognized taxonomy of Australian biodata. The AuNSL databases used by Hespi are the:
Australian Plant Name Index
Australian Bryophyte Name Index
Australian Fungi Name Index
Australian Lichen Name Index
Australian Algae Name Index
If the extracted text matches to a taxonomic name in the reference database with a similarity of 80% or more using the Gestalt (Ratcliff/Obershelp) approach, Hespi will assign the taxonomic name from the reference database to that field. In this way, minor differences of the taxon name/s on the specimen label or the extracted data to those in taxonomic reference databases are corrected. Such differences may be orthographic variants, incorrect spelling of the taxon name on the primary specimen label, or incorrect text recognition. The closeness of the matches indicate to Hespi whether to use the output from Tesseract or TrOCR when recording the text of the other fields. If no text recognition is found to be preferred (either because both generated the same score, or because neither had a similarity score over 80% and so were each given a score of 0), then handwritten or mixed labels will use the output from TrOCR and other labels will use output from Tesseract.
Large Language Model (LLM) Correction
After the text recognition, the results are passed through a multimodal large language model (LLM) to correct any errors. By default, Hespi uses OpenAI’s `gpt-4o’ model citep{openai2023gpt4}. This can be changed to any other model from OpenAI or Anthropic by specifying the model name on the command line. The LLM is prompted with the image of the primary specimen label, the list of the desired fields, the currently accepted text for each field and the outputs from the OCR and HTR engines and how the text has been adjusted after cross-checking with the relevant databases. The LLM is requested to output the text for any fields where the accepted text is incorrect. Currently, no examples of this process are provided through the prompt and so Hespi is using the LLM as a `zero-shot’ learner citep{Radford2019LanguageMA}. Hespi could be modified to provide the LLM with examples of images from a particular herbarium and so use the LLM as a `few-shot’ learner which will likely improve the results for similar primary specimen labels citep{few_shot}. This is left for future experimentation.
Outputs
The pipeline outputs are summarized as an HTML report which displays the cropped images from each model and the derived recognized text. In this way it is possible to manually cross-check the accuracy of the derived text by comparing it with the original data, visualized from the entire specimen label or the corresponding extracted data field. The CSV file includes the match score between 0 and 1 for the family, genus, species, and authority, alongside all OCR and HTR results. These scores are a value between 0 and 1, with 1 indicating a perfect match and no corrections made; 0.8 to 0.999 indicating how similar a match was, and 0 indicating no match found with a similarity of 80% or higher.